|
ИСПОЛЬЗОВАНИЕ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ ДЛЯ РАСПОЗНАВАНИЯ РУКОПЕЧАТНЫХ СИМВОЛОВ (Мисюрев А. В.)
Здесь Вы можете скачать статью Мисюрева А. В. (файл в формате Word (112 Kb).
 Рассматривается задача распознавания символов в анкетах, заполняемых от руки печатными буквами. Рассматривается задача распознавания символов в анкетах, заполняемых от руки печатными буквами.
Искусственные нейронные сети достаточно широко используются при распознавании символов (см., например, 1-3,6-9). Алгоритмы, использующие нейронные сети для распознавания символов, часто строятся следующим образом. Поступающее на распознавание изображение символа (растр) приводится к некоторому стандартному размеру. Как правило, используется растр размером 16х16 пикселов.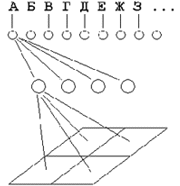
Значения яркости в узлах нормализованного растра используются в качестве входных параметров нейронной сети. Число выходных параметров нейронной сети равняется числу распознаваемых символов. Результатом распознавания является символ, которому соответствует наибольшее из значений выходного вектора нейронной сети (см. рисунок, показана только часть связей и узлов растра).  Повышение надежности таких алгоритмов связано, как правило, либо с поиском более информативных входных признаков, либо с усложнением структуры нейронной сети. Повышение надежности таких алгоритмов связано, как правило, либо с поиском более информативных входных признаков, либо с усложнением структуры нейронной сети.
Надежность распознавания и потребность программы в вычислительных ресурсах во многом зависят от выбора структуры и параметров нейронной сети. Нейронная сеть, разработанная для распознавания цифровых почтовых кодов (ZIP-кодов) описывается в (1). Изображения цифр приводятся к единому размеру (16х16 пикселов). Полученное изображение подается на вход нейронной сети, имеющей три внутренних уровня и 10 узлов в верхнем уровне. Нижние слои сети не являются полносвязанными. Узлы низшего уровня совместно используют общий набор весов. Все это, по замыслу разработчиков, должно повысить способность низших уровней сети к выделению первичных признаков в изображениях. Полученная таким образом нейронная сеть имеет 1256 узлов и 9760 независимых параметров. Для увеличения способности сети к обобщению и уменьшению объема необходимых вычислений и памяти проведено удаление слабо используемых весов. В результате число независимых параметров уменьшается в четыре раза. Обучение нейронной сети проведено на наборе из 7300 символов, тестирование на наборе из 2000 символов. Ошибки распознавания составляют приблизительно 1% на обучающем наборе и 5% на проверочном.
В качестве входных параметров нейронной сети вместо значений яркости в узлах нормализованного растра могут использоваться значения, характеризующие перепад яркости. Такие входные параметры позволяют лучше выделять края буквы. Система распознавания рукопечатных цифр, использующие такие входные параметры, описывается в (2). Поступающие на распознавание изображения приводятся к размеру 16х16 пикселов. После этого они подвергаются дополнительной обработке с целью выделения участков с наибольшими перепадами в яркости. Используемая нейронная сеть имеет только один внутренний уровень, но применяется совместно с другими алгоритмами. Обучение и тестирование проведено на символах, взятых из трех независимых баз данных. Из каждой базы данных используется от 4000 до 6000 символов на обучение и от 2000 до 4000 символов на тестирование. Процент ошибок существенно меняется в зависимости от базы данных, на которых проводится тестирование и составляет 0.60%-2.2%.
Одним из широко используемых методов повышения точности распознавания является одновременное использование нескольких различных распознающих модулей и последующее объединение полученных результатов (например, путем голосования). При этом очень важно, чтобы алгоритмы, используемые этими модулями, были как можно более независимы. Это может достигаться как за счет использования распознающих модулей, использующих принципиально различные алгоритмы распознавания, так и специальным подбором обучающих данных.
Один из таких методов был предложен несколько лет назад и основан на использовании трех распознающих модулей (машин) (4,5). Первая машина обучается обычным образом. Вторая машина обучается на символах, которые были отфильтрованы первой машиной таким образом, что вторая машина видит смесь символов, 50% из которых были распознаны первой машиной верно и 50% неверно. Наконец, третья машина обучается на символах, на которых результаты распознавания 1-ой и 2-ой машин различны. При тестировании распознаваемые символы подаются на вход всем трем машинам. Оценки, получаемые на выходе всех трех машин складываются. Символ, получивший наибольшую суммарную оценку выдается в качестве результата распознавания.
|
